8-element Vector{String}:
"sentence_id"
"doc_id"
"date"
"event_type"
"label"
"sentence"
"score"
"speaker"💰 Trillion Dollar Words in Julia
JuliaCon 2024
Thursday, July 11, 2024
TrillionDollarWords.jl





A light-weight package providing Julia users easy access to the Trillion Dollar Words dataset and model (Shah et al. 2023).
Context
ICML 2024 paper Stop Making Unscientific AGI Performance Claims (Altmeyer et al. 2024) (preprint, blog post, code):
- Even simple models can distill meaningful information that predicts external data.
- Humans are prone to seek patterns and anthropomorphize.

“There! It’s sentient!”

Motivation
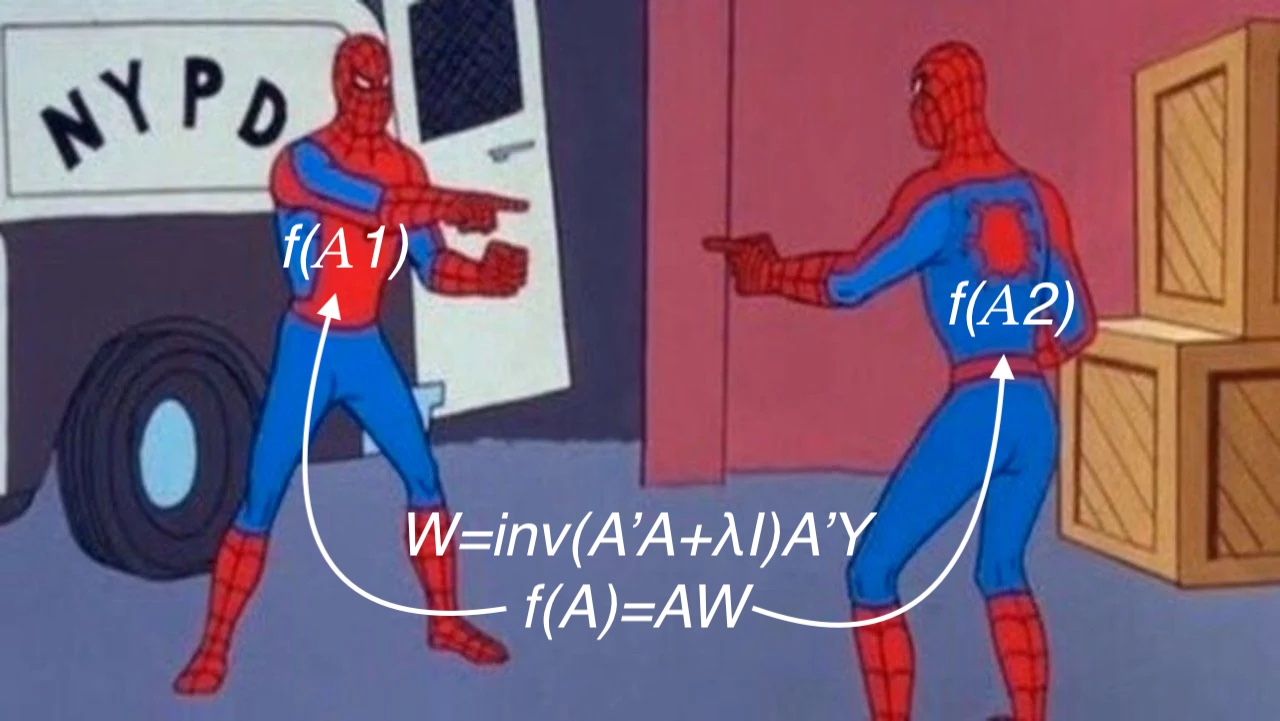
- \(A_1\): \(enc(\)„It is essential to bring inflation back to target to avoid drifting into deflation territory.“\()\)
- \(A_2\): \(enc(\)„It is essential to bring the numbers of doves back to target to avoid drifting into dovelation territory.“\()\)
“They’re exactly the same.”
— Linear probe \(\widehat{cpi}=f(A)\)
Embedding FOMC comms
- We linearly probe all layers to predict unseen economic indicators (CPI, PPI, UST yields).
- Predictive power increases with layer depth and probes outperform simple AR(\(p\)) models.

Sparks of Economic Understanding?
If probe results were indicative of some intrinsic ‘understanding’, probe should not be sensitive to unrelated sentences.

Questions?
With thanks to my co-authors Andrew M. Demetriou, Antony Bartlett, and Cynthia C. S. Liem and to the audience for their attention.
