SmartPolicy Recommender System
AI Risks, Mitigation and Maintenance
Dr Patrick Altmeyer
Delft University of Technology
2026-03-27
Introduction
SmartPolicy
- Goal: recommender system (RS) for insurance policies
- why? more tailored customer experience
- How-to: use granular data and expressive models to train RS
- data on demographics , prior claims , driving , health , home
- models likely to include opaque machine learning
ERGO context
Pan-European insurer (Munich Re subsidiary), operating across EU, US, and Asia
SmartPolicy
- How-to: use granular data and powerful models to train RS
- all data sources likely to include sensitive data
- Applicable: GDPR Art. 9 (special categories), Art. 22 (automated decisions), Art. 35 (Data Protection Impact Assessment)
- more powerful models likely not explainable
- Applicable: EU AI Act (high-risk obligations), GDPR Art. 22 (right to explanation)
- all data sources likely to include sensitive data
Applicable Regulation
EU Regulation: AI Act
- Article 6 (High-Risk AI Systems1)
- “[…] AI system performs profiling of natural persons”
- “AI systems for risk assessment and pricing in life and health insurance”—Annex III §5(c)
- all data sources (except ) directly affected
- Article 26 (obligations): risk management system, data governance, technical documentation, human oversight, conformity assessment, registration in EU database.
- Article 27: Fundamental Rights Impact Assessment (FRIA) for High-Risk AI Systems
EU Regulation: GDPR
| Article | Relevance to SmartPolicy |
|---|---|
| Art. 5 | Data minimisation: collect only what is strictly necessary |
| Art. 9 | Special categories: health, driving behaviour data require explicit consent or legal basis |
| Art. 22 | Automated decisions: right not to be subject to solely automated decisions with significant effects; special-category data further restricted |
| Art. 35 | DPIA mandatory when processing sensitive data at scale for profiling (definitely , ) |
Beyond EU: United States
- USA: No unified federal AI-in-insurance law; oversight is state-driven and fragmented
- A patchwork of state rules creates compliance complexity for multi-state operations.
- Asia: country-specific and complex; China, for example, still lacks standalone, comprehensive statute.
Tip
Recommendation: prioritise EU rollout first. The EU AI Act provides a clear, comprehensive framework.
AI-related Risks
Specific Risks: Data
- Sensitive variables included directly: data (Art. 9 special category)
- Proxies of sensitive variables: as proxy for ethnicity; may encode gender, religion, disability
- Historical bias: past data likely reflects structural under/over-reporting by vulnerable groups
- Data minimisation violation (GDPR Art. 5): temptation to use all available data for data-hungry models
Specific Risks: Models
- Opacity: most competitive RS are inherently black-box — violates GDPR Art. 22 right to explanation and EU AI Act transparency requirements.
- Historical bias: models are representations of training data.
- Adversarial vulnerability: e.g. fake claim histories
- Data drift → model drift: insurance risk profiles shift over time (e.g. post-pandemic , EV adoption for ); models degrade silently without monitoring
- Membership inference attacks: genuine privacy risk for sensitive , ,
Mitigation Strategies
Technical Mitigations: Opaque Models
- Start simple: use interpretable models where feasible (e.g. collaborative filtering; GAMs instead of DL; …)
- Post-hoc explainability and recourse: e.g. counterfactual explanations “what would change my recommendation?”
- Fairness-aware training: adversarial debiasing and mitigation (Fairlearn, Holistic AI), counterfactual training, …
- Human-in-the-loop for high-stakes outputs (e.g. refusal to recommend any policy)—required by EU AI Act Art. 14
Technical Mitigations: Robustness
- Uncertainty quantification: Bayesian or ensemble methods; conformal prediction.
- Adversarial training: train on perturbed inputs and/or use data augmentation techniques (e.g. counterfactuals)
- Drift detection: monitor input/output distributions
Technical Mitigations: Data
- Data minimisation (GDPR Art. 25):
- small \(p\): define the minimal feature set for each insurance line before modelling
- small \(n\): (Bayesian) active learning -> sample high-uncertainty inputs
- Proxy audits: test for and remove non-sensitive features correlated with sensitive features especially in , , (use e.g. Fairlearn)
Governance Mitigations: Data
- Data governance policy: define data retention periods, deletion procedures, consent management
- Datasheets for Datasets (Gebru et al., 2021): clear guidelines for documenting training data (see FOSS implementation)
- Mandatory DPIA before deployment (GDPR Art. 35): purpose, legal basis, risks, and controls; update at each major model revision (definitely , , likely all)
Governance Mitigations: Models
- Model cards (Mitchell et al., 2019, arXiv:1810.03993: document model, intended use, limitations, training data, …
- Markdown with YAML as already standard practice on HuggingFace
- Version control: model and data linked on HF; consider semantic versioning
- Internal red-teaming: structured adversarial testing sessions and hackathons
- Regular retraining schedule: define a model lifecycle policy
Governance Mitigations: End-to-end
End-to-end auditing framework as reference point:
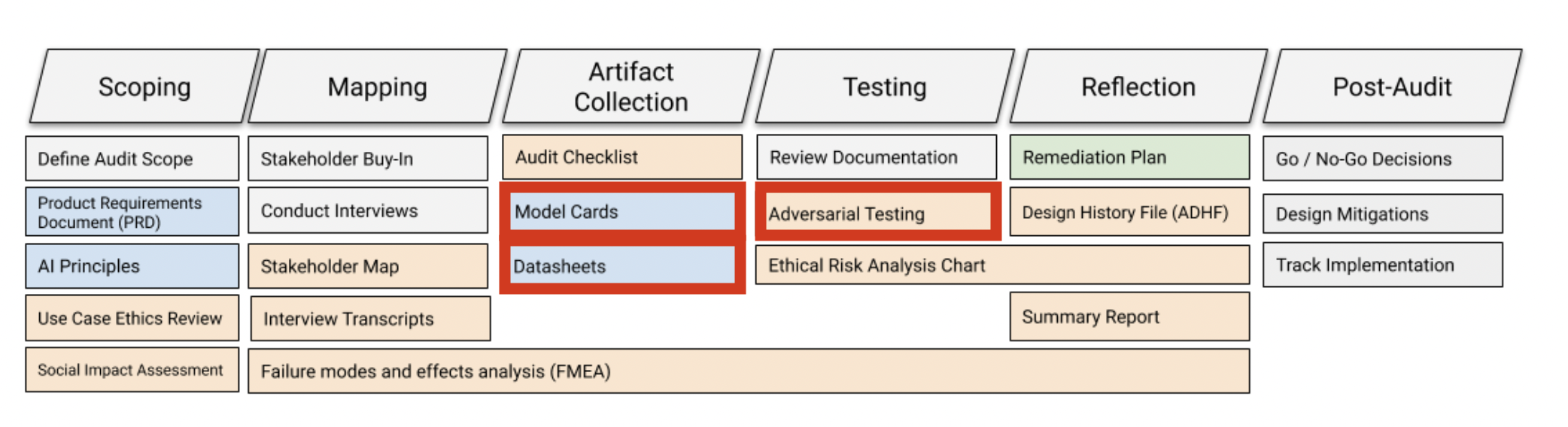
Governance Mitigations — Open Source Considerations
- Selectively open-sourcing code and models can generate external scrutiny, bug reports, and reputational goodwill
- Open-source models carry inherent risks: membership inference attacks become easier
FOSS Practices
In the FOSS space, essentially all code is treated packages (facilitates usage, extensibility, …)
Documentation
Key Documents1
| Document | Trigger | |
|---|---|---|
| Datasheets (Gebru et al., 2021) | Per training dataset | |
| Model cards (Mitchell et al., 2019) | Per model release | |
| Technical documentation (EU AI Act Art. 11) | commit; PR; release |
Notes on Technical Documentation
- Treating all code as packages facilitates proper technical documentation standards.
- Language-specific support is well-established (e.g. Julia).
- Rely on Markdown (README.md, CHANGELOG.md, …) for version-controlled documentation.
- Easily ingested by Quarto for publishing polished outputs
- Ideal for providing context to LLMs/agents.
Target Audience — Internal
- Data scientists and ML engineers: model cards, datasheets, technical documentation, version-controlled code and experiment logs.
- Customer-facing staff: must be able to explain any recommendation and handle contestation (EU AI Act Art. 14, GDPR Art. 22(3))
- Compliance and legal: DPIA, FRIA, …
- Management: use Quarto to go from Markdown to PDF, HTML, websites, presentations (like this one!), …
Target Audience — External
- Regulators (BaFin, national DPAs, EIOPA): technical documentation, DPIA, FRIA, conformity assessment records — subject to inspection under EU AI Act Art. 74
- Customers: simplified explanation notices (why was this policy recommended?); right to contest automated decisions (GDPR Art. 22); privacy notice under GDPR Art. 13
- Open-source community (if applicable): public model cards, fairness evaluation results, code documentation — supports external red-teaming and transparency signalling
Keeping Documentation Up-to-Date
- If above is properly implemented, state of documentation will always be consistent with the state of:
- Data (datasheets)
- Models (model cards)
- Code (technical docs)
- Recommending HuggingFace for 1-2, GitHub/Gitlab for 3.
Questions?
![]()