Explaining Black-Box Models through Counterfactuals
Patrick Altmeyer 
We present CounterfactualExplanations.jl: a package for generating Counterfactual Explanations (CE) and Algorithmic Recourse (AR) for black-box models in Julia. CE explain how inputs into a model need to change to yield specific model predictions. Explanations that involve realistic and actionable changes can be used to provide AR: a set of proposed actions for individuals to change an undesirable outcome for the better. In this article, we discuss the usefulness of CE for Explainable Artificial Intelligence and demonstrate the functionality of our package. The package is straightforward to use and designed with a focus on customization and extensibility. We envision it to one day be the go-to place for explaining arbitrary predictive models in Julia through a diverse suite of counterfactual generators.
Julia, Explainable Artificial Intelligence, Counterfactual Explanations, Algorithmic Recourse
1 Introduction
Machine Learning models like Deep Neural Networks have become so complex and opaque over recent years that they are generally considered black-box systems. This lack of transparency exacerbates several other problems typically associated with these models: they tend to be unstable (Goodfellow, Shlens, and Szegedy 2014), encode existing biases (Buolamwini and Gebru 2018) and learn representations that are surprising or even counter-intuitive from a human perspective (Buolamwini and Gebru 2018). Nonetheless, they often form the basis for data-driven decision-making systems in real-world applications.
As others have pointed out, this scenario gives rise to an undesirable principal-agent problem involving a group of principals—i.e. human stakeholders—that fail to understand the behaviour of their agent—i.e. the black-box system (Borch 2022). The group of principals may include programmers, product managers and other decision-makers who develop and operate the system as well as those individuals ultimately subject to the decisions made by the system. In practice, decisions made by black-box systems are typically left unchallenged since the group of principals cannot scrutinize them:
“You cannot appeal to (algorithms). They do not listen. Nor do they bend.” (O’Neil 2016)
In light of all this, a quickly growing body of literature on Explainable Artificial Intelligence (XAI) has emerged. Counterfactual Explanations fall into this broad category. They can help human stakeholders make sense of the systems they develop, use or endure: they explain how inputs into a system need to change for it to produce different decisions. Explainability benefits internal as well as external quality assurance. Explanations that involve plausible and actionable changes can be used for Algorithmic Recourse (AR): they offer the group of principals a way to not only understand their agent’s behaviour but also adjust or react to it.
The availability of open-source software to explain black-box models through counterfactuals is still limited. Through the work presented here, we aim to close that gap and thereby contribute to broader community efforts towards XAI. We envision this package to one day be the go-to place for Counterfactual Explanations in Julia. Thanks to Julia’s unique support for interoperability with foreign programming languages we believe that this library may also benefit the broader machine learning and data science community.
Our package provides a simple and intuitive interface to generate CE for many standard classification models trained in Julia, as well as in Python and R. It comes with detailed documentation involving various illustrative example datasets, models and counterfactual generators for binary and multi-class prediction tasks. A carefully designed package architecture allows for a seamless extension of the package functionality through custom generators and models.
The remainder of this article is structured as follows: Section 2 presents related work on XAI as well as a brief overview of the methodological framework underlying CE. Section 3 introduces the Julia package and its high-level architecture. Section 4 presents several basic and advanced usage examples. In Section 5 we demonstrate how the package functionality can be customized and extended. To illustrate its practical usability, we explore examples involving real-world data in Section 6. Finally, we also discuss the current limitations of our package, as well as its future outlook in Section 7. Section 8 concludes.
3 Introducing: CounterfactualExplanations.jl
Figure 1 provides an overview of the package architecture. It is built around two core modules that are designed to be as extensible as possible through dispatch: 1) Models is concerned with making any arbitrary model compatible with the package; 2) Generators is used to implement counterfactual search algorithms. The core function of the package—generate_counterfactual—uses an instance of type <:AbstractFittedModel produced by the Models module and an instance of type <:AbstractGenerator produced by the Generators module. Relating this to the methodology outlined in Section 2.2, the former instance corresponds to the model \(M\), while the latter defines the rules for the counterfactual search (Equation 2).
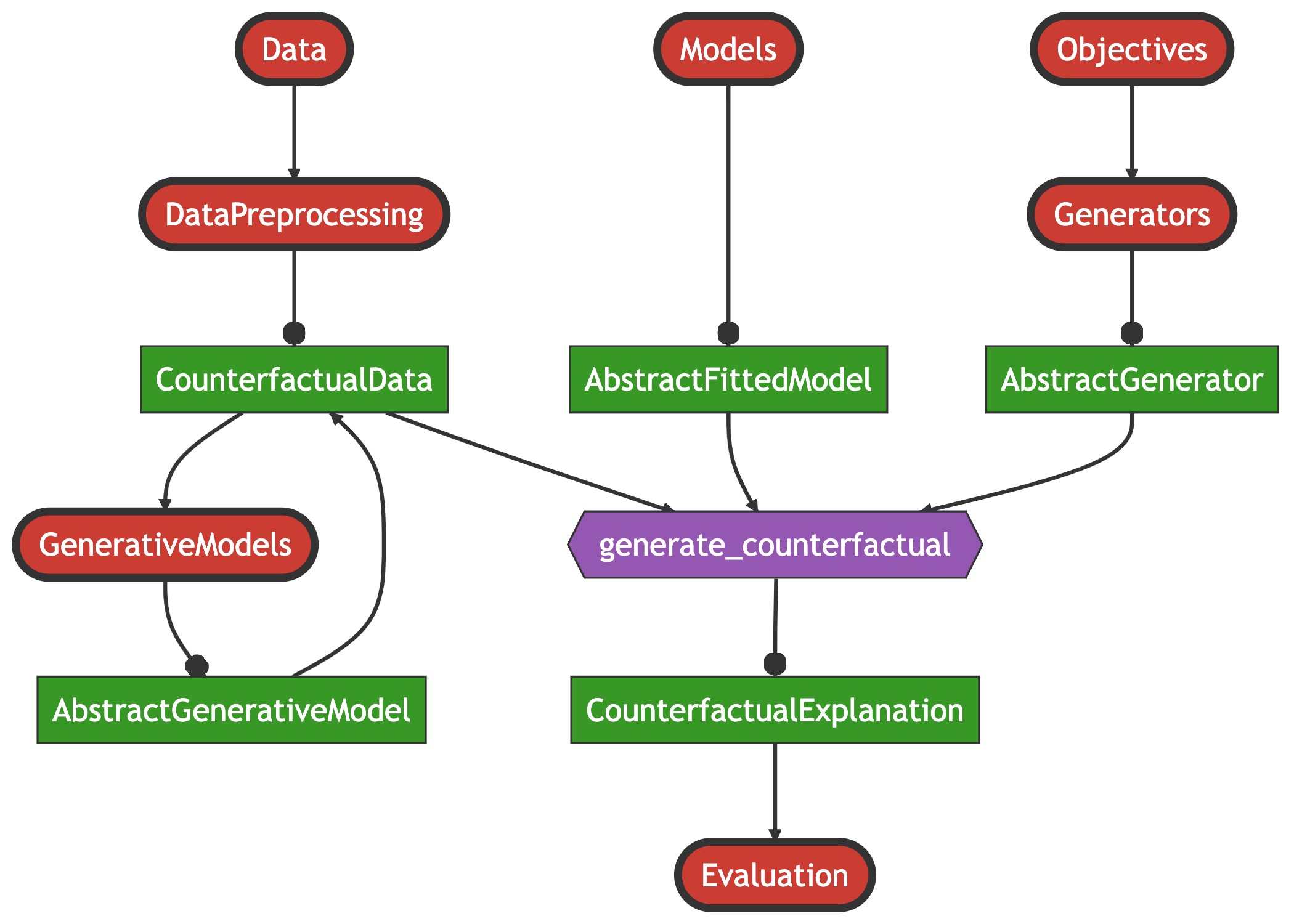
3.1 Models
The package currently offers native support for models built and trained in Flux (Innes 2018) as well as a small subset of models made available through MLJ (Blaom et al. 2020). While in general it is assumed that users resort to this package to explain their pre-trained models, we provide a simple API call to train the following models:
- Linear Classifier (Logistic Regression and Multinomial Logit)
- Multi-Layer Perceptron (Deep Neural Network)
- Deep Ensemble Lakshminarayanan, Pritzel, and Blundell (2016)
- Decision Tree, Random Forest, Gradient Boosted Trees
As we demonstrate below, it is straightforward to extend the package through custom models. Support for torch models trained in Python or R is also available.4
3.2 Generators
A large and growing number of counterfactual generators have already been implemented in our package (Table 1). At a high level, we distinguish generators in terms of their compatible model types, their default search space, and their composability. All “gradient-based” generators are compatible with differentiable models, e.g. Flux and torch, while “tree-based” generators are only applicable to models that involve decision trees. Concerning the search space, it is possible to search counterfactuals in a lower-dimensional latent embedding of the feature space that implicitly encodes the data-generating process (DGP). To learn the latent embedding, existing work has typically relied on generative models or existing causal knowledge (Joshi et al. 2019; Karimi, Schölkopf, and Valera 2021). While this notion is compatible with all of our gradient-based generators, only some generators search a latent space by default. Finally, composability implies that the given generator can be blended with any other composable generator, which we discuss in Section 4.2.
Beyond these broad technical distinctions, generators largely differ in terms of how they address the various desiderata mentioned above: ClapROAR aims to preserve the classifier, i.e. to generate counterfactuals that are robust to endogenous model shifts (Altmeyer et al. 2023); CLUE searches plausible counterfactuals in the latent embedding of a generative model by explicitly minimising predictive entropy (Antorán et al. 2020); DiCE is designed to generate multiple, maximally diverse counterfactuals (Mothilal, Sharma, and Tan 2020); FeatureTweak leverages the internals of decision trees to search counterfactuals on a feature-by-feature basis, finding the counterfactual that tweaks the features in the least costly way (Tolomei et al. 2017); Gravitational aims to generate plausible and robust counterfactuals by minimising the distance to observed samples in the target class (Altmeyer et al. 2023); Greedy aims to generate plausible counterfactuals by implicitly minimising predictive uncertainty of Bayesian classifiers (Schut et al. 2021); GrowingSpheres is model-agnostic, relying solely on identifying nearest neighbours of counterfactuals in the target class by gradually increasing the search radius and then moving counterfactuals in that direction(Laugel et al. 2017); PROBE generates probabilistically robust counterfactuals (Pawelczyk et al. 2022); REVISE addresses the need for plausibility by searching counterfactuals in the latent embedding of a Variational Autoencoder (VAE) (Joshi et al. 2019); Wachter is the baseline approach that only penalises the distance to the original sample (Wachter, Mittelstadt, and Russell 2017).
| Generator | Model Type | Search Space | Composable |
|---|---|---|---|
| ClaPROAR (Altmeyer et al. 2023) | gradient based | feature | yes |
| CLUE (Antorán et al. 2020) | gradient based | latent | yes |
| DiCE (Mothilal, Sharma, and Tan 2020) | gradient based | feature | yes |
| FeatureTweak (Tolomei et al. 2017) | tree based | feature | no |
| Gravitational (Altmeyer et al. 2023) | gradient based | feature | yes |
| Greedy (Schut et al. 2021) | gradient based | feature | yes |
| GrowingSpheres (Laugel et al. 2017) | agnostic | feature | no |
| PROBE (Pawelczyk et al. 2022) | gradient based | feature | no |
| REVISE (Joshi et al. 2019) | gradient based | latent | yes |
| Wachter (Wachter, Mittelstadt, and Russell 2017) | gradient based | feature | yes |
3.3 Data Catalogue
To allow researchers and practitioners to test and compare counterfactual generators, the package ships with catalogues of pre-processed synthetic and real-world benchmark datasets from different domains. Real-world datasets include:
- Adult Census (Barry Becker 1996)
- California Housing (Pace and Barry 1997)
- CIFAR10 (Krizhevsky 2009)
- German Credit (Hoffman 1994)
- Give Me Some Credit (Kaggle 2011)
- MNIST (LeCun 1998) and Fashion MNIST (Xiao, Rasul, and Vollgraf 2017)
- UCI defaultCredit (Yeh and Lien 2009)
Custom datasets can also be easily preprocessed as explained in the documentation.
3.4 Plotting
The package also extends common Plots.jl methods to facilitate the visualization of results. Calling the generic plot() method on an instance of type <:CounterfactualExplanation, for example, generates a plot visualizing the entire counterfactual path in the feature space5. We will see several examples of this below.
4 Basic Usage
In the following, we begin our exploration of the package functionality with a simple example. We then demonstrate how more advanced generators can be easily composed and show how users can impose mutability constraints on features. Finally, we also briefly explore the topics of counterfactual evaluation and benchmarking.
4.1 A Simple Generic Generator
Code \(\ref{lst:simple}\) below provides a complete example demonstrating how the framework presented in Section 2.2 can be implemented through our package. Using a synthetic data set with linearly separable features we first fit a linear classifier (line \(\ref{line:simple-class}\)). Next, we define the target class (line \(\ref{line:simple-t}\)) and then draw a random sample from the other class (line \(\ref{line:simple-x}\)). Finally, we instantiate a generic generator (line \(\ref{line:simple-gen}\)) and run the counterfactual search (line \(\ref{line:simple-search}\)). Figure 2 illustrates the resulting counterfactual path in the two-dimensional feature space. Features go through iterative perturbations until the desired confidence level is reached as illustrated by the contour in the background, which shows the softmax output for the target class.
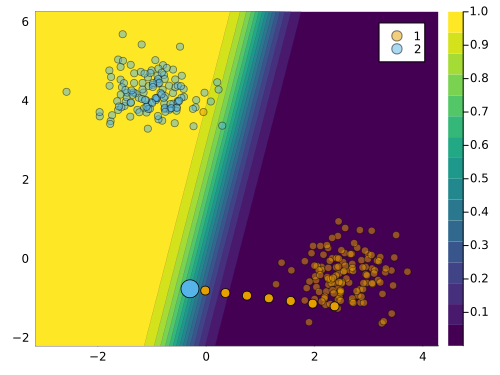
In this simple example, the generic generator produces a valid counterfactual, since the decision boundary is crossed and the predicted label is flipped. But the counterfactual is not plausible: it does not appear to be generated by the same DGP as the observed data in the target class. This is because the generic generator does not take into account any of the desiderata mentioned in Section 2.2, except for the distance to the factual sample.
4.2 Composing Generators
To address these issues, we can leverage the ideas underlying some of the more advanced counterfactual generators introduced above. In particular, we will now show how easy it is to compose custom generators that blend different ideas through user-friendly macros.
Suppose we wanted to address the desiderata of plausibility and diversity. We could do this by blending ideas underlying the DiCE generator with the REVISE generator. Formally, the corresponding search objective would be defined as follows,
\[ \mathbf{Z}^\prime = \arg \min_{\mathbf{Z}^\prime \in \mathcal{Z}^{L \times K}} \{ {\ell(M(f(\mathbf{Z}^\prime)),t)} + \lambda \cdot {\text{diversity}(f(\mathbf{Z}^\prime)) } \} \tag{3}\]
where \(\mathbf{X}^\prime\) is an \(L\)-dimensional array of counterfactuals, \(f: \mathcal{Z}^{L \times K} \mapsto \mathcal{X}^{L \times D}\) is a function that maps the \(L \times K\)-dimensional latent space \(\mathcal{Z}\) to the \(L \times D\)-dimensional feature space \(\mathcal{X}\) and \(\text{diversity}(\cdot)\) is the penalty proposed by Mothilal, Sharma, and Tan (2020) that induces diverse sets of counterfactuals. As in Equation 2, \(\ell\) is the loss function, \(M\) is the black-box model, \(t\) is the target class, and \(\lambda\) is the strength of the penalty.
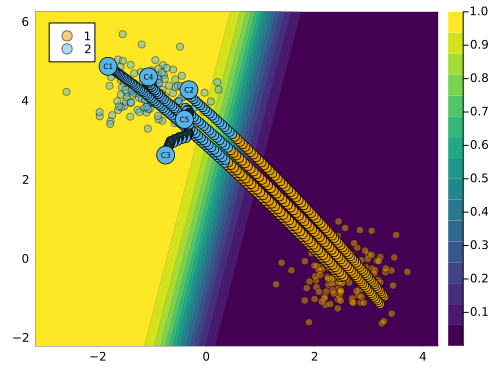
Code \(\ref{lst:composed}\) demonstrates how Equation 3 can be seamlessly translated into Julia code. We begin by instantiating a GradientBasedGenerator in line \(\ref{line:composed-init}\). Next, we use chained macros for composition: firstly, we define the counterfactual search @objective corresponding to DiCE in line \(\ref{line:composed-dice}\); secondly, we define the latent space search strategy corresponding to REVISE using the @search_latent_space macro in line \(\ref{line:composed-latent}\); finally, we specify our prefered optimisation method using the @with_optimiser macro in line \(\ref{line:composed-adam}\).
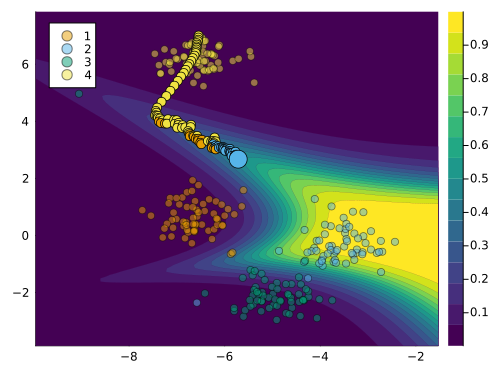
In this case, the counterfactual search is performed in the latent space of a Variational Autoencoder (VAE) that is automatically trained on the observed data. It is important to specify the keyword argument num_counterfactuals of the generate_counterfactual to some value higher than \(1\) (default), to ensure that the diversity penalty is effective. The resulting counterfactual path is shown in Figure 3 below. We observe that the resulting counterfactuals are diverse and the majority of them are plausible.
4.3 Mutability Constraints
In practice, features usually cannot be perturbed arbitrarily. Suppose, for example, that one of the features used by a bank to predict the creditworthiness of its clients is age. If a counterfactual explanation for the prediction model indicates that older clients should “grow younger” to improve their creditworthiness, then this is an interesting insight (it reveals age bias), but the provided recourse is not actionable. In such cases, we may want to constrain the mutability of features. To illustrate how this can be implemented in our package, we will continue with the example from above.
Mutability can be defined in terms of four different options: 1) the feature is mutable in both directions, 2) the feature can only increase (e.g. age), 3) the feature can only decrease (e.g. time left until your next deadline) and 4) the feature is not mutable (e.g. skin colour, ethnicity, …). To specify which category a feature belongs to, users can pass a vector of symbols containing the mutability constraints at the pre-processing stage. For each feature one can choose from these four options: :both (mutable in both directions), :increase (only up), :decrease (only down) and :none (immutable). By default, nothing is passed to that keyword argument and it is assumed that all features are mutable in both directions.6
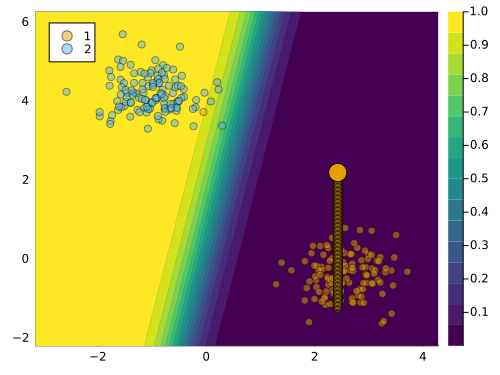
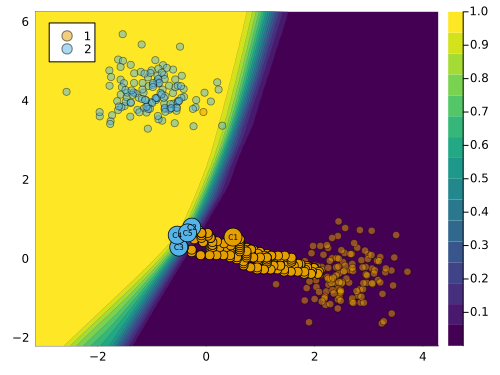
We can impose that the first feature is immutable as follows: counterfactual_data.mutability = [:none, :both]. The resulting counterfactual path is shown in Figure 4 below. Since only the second feature can be perturbed, the sample can only move along the vertical axis. In this case, the counterfactual search does not yield a valid counterfactual, since the target class is not reached.
4.4 Evaluation and Benchmarking
The package also makes it easy to evaluate counterfactuals with respect to many of the desiderata mentioned above. For example, users may want to infer how costly the provided recourse is to individuals. To this end, we can measure the distance of the counterfactual from its original value. The API call to compute the distance metric defined in Wachter, Mittelstadt, and Russell (2017), for instance, is as simple as evaluate(ce; measure=distance_mad), where ce can also be a vector of CounterfactualExplanations.
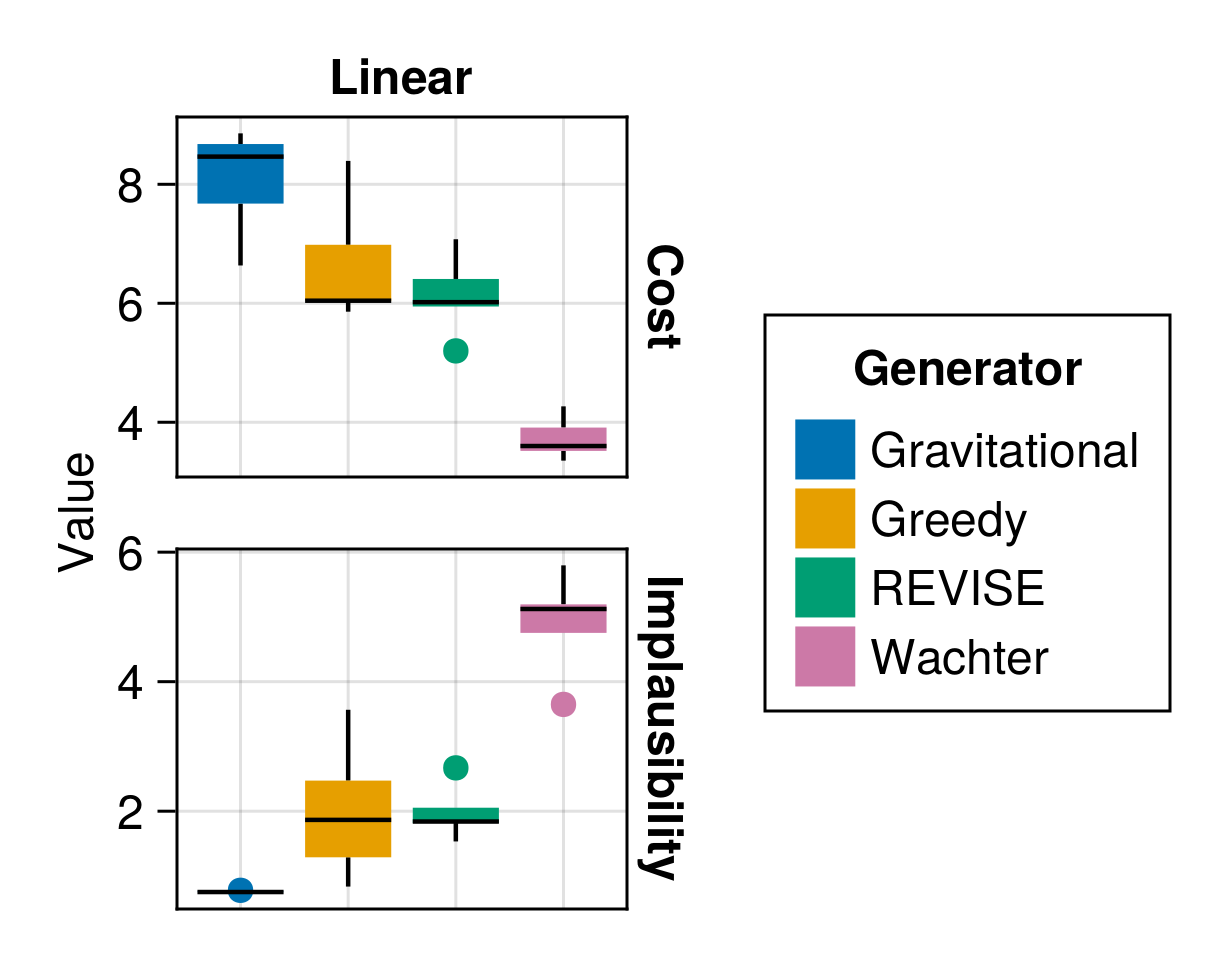
Additionally, the package provides a benchmarking framework that allows users to compare the performance of different generators on a given dataset. In Figure 5 we show the results of a benchmark comparing several generators in terms of the average cost and implausibility of the generated counterfactuals. The cost is proxied by the L1-norm of the difference between the factual and counterfactual features, while implausibility is measured by the distance of the counterfactuals from samples in the target class. The results illustrate that there is a tradeoff between minimizing costs to individuals and generating plausible counterfactuals.
5 Customization and Extensibility
One of our priorities has been to make our package customizable and extensible. In the long term, we aim to add support for more default models and counterfactual generators. In the short term, it is designed to allow users to integrate models and generators themselves. These community efforts will facilitate our long-term goals.
5.1 Adding Custom Models
At the high level, only two steps are necessary to make any supervised learning model compatible with our package:
- : We need to subtype the .
- : The functions and need to be extended through custom methods for the model in question.
To demonstrate how this can be done in practice, we will reiterate here how native support for Flux.jl (Innes 2018) deep learning models was enabled.7 Once again we use synthetic data for an illustrative example. Code \(\ref{lst:nn}\) below builds a simple model architecture that can be used for a multi-class prediction task. Note how outputs from the final layer are not passed through a softmax activation function, since the counterfactual loss is evaluated with respect to logits as we discussed earlier. The model is trained with dropout.
Code \(\ref{lst:mymodel}\) below implements the two steps that were necessary to make Flux models compatible with the package. In line \(\ref{line:mymodel-subtype}\) we declare our new struct as a subtype of AbstractDifferentiableModel, which itself is an abstract subtype of AbstractFittedModel.8 Computing logits amounts to just calling the model on inputs. Predicted probabilities for labels can be computed by passing logits through the softmax function.
The API call for generating counterfactuals for our new model is the same as before. Figure 6 shows the resulting counterfactual path for a randomly chosen sample. In this case, the contour shows the predicted probability that the input is in the target class (\(t=2\)).
5.2 Adding Custom Generators
In some cases, composability may not be sufficient to implement specific logics underlying certain counterfactual generators. In such cases, users may want to implement custom generators. To illustrate how this can be done we will consider a simple extension of our GenericGenerator. As we have seen above, Counterfactual Explanations are not unique. In light of this, we might be interested in quantifying the uncertainty around the generated counterfactuals (Delaney, Greene, and Keane 2021). One idea could be, to use dropout to randomly switch features on and off in each iteration. Without dwelling further on the merit of this idea, we will now briefly show how this can be implemented.
5.2.1 A Generator with Dropout
Code \(\ref{lst:dropout}\) below implements two important steps: 1) create an abstract subtype of the AbstractGradientBasedGenerator and 2) create a constructor with an additional field for the dropout probability.
Next, in Code \(\ref{lst:generate}\) we define how feature perturbations are generated for our custom dropout generator: in particular, we extend the relevant function through a method that implements the dropout logic.
Finally, we proceed to generate counterfactuals in the same way we always do. The resulting counterfactual path is shown in Figure 7.
6 A Real-World Examples
Now that we have explained the basic functionality of CounterfactualExplanations.jl through some synthetic examples, it is time to work through examples involving real-world data.
6.1 Give Me Some Credit
The Give Me Some Credit dataset is one of the tabular real-world datasets that ship with the package (Kaggle 2011). It can be used to train a binary classifier to predict whether a borrower is likely to experience financial difficulties in the next two years. In particular, we have an output variable \(y \in \{0=\texttt{no stress},1=\texttt{stress}\}\) and a feature matrix \(X\) that includes socio-demographic variables like age and income. A retail bank might use such a classifier to determine if potential borrowers should receive credit or not.
For the classification task, we use a Multi-Layer Perceptron with dropout regularization. Using the Gravitational generator (Altmeyer et al. 2023) we will generate counterfactuals for ten randomly chosen individuals that would be denied credit based on our pre-trained model. Concerning the mutability of features, we only impose that the age cannot be decreased.
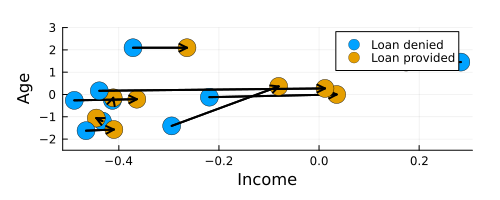
Figure 8 shows the resulting counterfactuals proposed by Wachter in the two-dimensional feature space spanned by the age and income variables. An increase in income and age is recommended for the majority of individuals, which seems plausible: both age and income are typically positively related to creditworthiness.
6.2 MNIST
For our second example, we will look at image data. The MNIST dataset contains 60,000 training samples of handwritten digits in the form of 28x28 pixel grey-scale images (LeCun 1998). Each image is associated with a label indicating the digit (0-9) that the image represents. The data makes for an interesting case study of CE because humans have a good idea of what plausible counterfactuals of digits look like. For example, if you were asked to pick up an eraser and turn the digit in the left panel of Figure 9 into a four (4) you would know exactly what to do: just erase the top part.
On the model side, we will use a simple multi-layer perceptron (MLP). Code \(\ref{lst:mnist-setup}\) loads the data and the pre-trained MLP. It also loads two pre-trained Variational Auto-Encoders, which will be used by our counterfactual generator of choice for this task: REVISE.
The proposed counterfactuals are shown in Figure 9. In the case in which REVISE has access to an expressive VAE (centre), the result looks convincing: the perturbed image does look like it represents a four (4). In terms of explainability, we may conclude that removing the top part of the handwritten nine (9) leads the black-box model to predict that the perturbed image represents a four (4). We should note, however, that the quality of counterfactuals produced by REVISE hinges on the performance of the underlying generative model, as demonstrated by the result on the right. In this case, REVISE uses a weak VAE and the resulting counterfactual is invalid. In light of this, we recommend using Latent Space search with care.

7 Discussion and Outlook
We believe that this package in its current form offers a valuable contribution to ongoing efforts towards XAI in Julia. That being said, there is significant scope for future developments, which we briefly outline in this final section.
7.1 Candidate models and generators
The package supports various models and generators either natively or through minimal augmentation. In future work, we would like to prioritize the addition of further predictive models and generators. Concerning the former, it would be useful to add native support for any supervised models built in MLJ.jl, an extensive Machine Learning framework for Julia (Blaom et al. 2020). This may also involve adding support for regression models as well as additional non-differentiable models. In terms of counterfactual generators, there is a list of recent methodologies that we would like to implement including MINT (Karimi, Schölkopf, and Valera 2021), ROAR (Upadhyay, Joshi, and Lakkaraju 2021) and FACE (Poyiadzi et al. 2020).
7.2 Additional datasets
For benchmarking and testing purposes it will be crucial to add more datasets to our library. We have so far prioritized tabular datasets that have typically been used in the literature on counterfactual explanations including Adult, Give Me Some Credit and German Credit (Karimi, Barthe, et al. 2020). There is scope for adding data sources that have so far not been explored much in this context including additional image datasets as well as audio, natural language and time-series data.
8 Concluding remarks
CounterfactualExplanation.jl is a package for generating Counterfactual Explanations and Algorithmic Recourse in Julia. Through various synthetic and real-world examples, we have demonstrated the basic usage of the package as well as its extensibility. The package has already served us in our research to benchmark various methodological approaches to Counterfactual Explanations and Algorithmic Recourse. We therefore strongly believe that it should help other practitioners and researchers in their own efforts towards Trustworthy AI.
We envision this package to one day constitute the go-to place for explaining arbitrary predictive models through an extensive suite of counterfactual generators. As a major next step, we aim to make our library as compatible as possible with the popular MLJ.jl package for machine learning in Julia. We invite the Julia community to contribute to these goals through usage, open challenge and active development.
9 Acknowledgements
We are immensely grateful to the group of TU Delft students who contributed huge improvements to this package as part of a university project in 2023: Rauno Arike, Simon Kasdorp, Lauri Kesküll, Mariusz Kicior, Vincent Pikand. We also want to thank the broader Julia community for being welcoming and open and for supporting research contributions like this one. Some of the members of TU Delft were partially funded by ICAI AI for Fintech Research, an ING—TU Delft collaboration.
10 References
Footnotes
Implementations of loss functions with respect to logits are often numerically more stable. For example, the
logitbinarycrossentropy(ŷ, y)implementation inFlux.Losses(used here) is more stable than the mathematically equivalentbinarycrossentropy(ŷ, y).↩︎While we were writing this paper, the
Rpackagecounterfactualswas released (Dandl et al. 2023). The developers seem to also envision a unifying framework, but the project appears to still be in its early stages.↩︎For details, see the Google Summer of Code 2022 project proposal: https://julialang.org/jsoc/gsoc/MLJ/#interpretable_machine_learning_in_julia.↩︎
We are currently relying on
PythonCall.jlandRCall.jland this functionality is still somewhat brittle. Since this is more of an edge case, we may move this feature into its own package in the future.↩︎For multi-dimensional input data, standard dimensionality reduction techniques are used to compress the data. In this case, the classifier’s decision boundary is approximated through a Nearest Neighbour model. This is still somewhat experimental and will be improved in the future.↩︎
Mutability constraints are not yet implemented for Latent Space search.↩︎
Flux models are now natively supported by our package and can be instantiated by calling
FluxModel().↩︎Note that in line \(\ref{line:mymodel-likelihood}\) we also provide a field determining the likelihood. This is optional and only used internally to determine which loss function to use in the counterfactual search. If this field is not provided to the model, the loss function needs to be explicitly supplied to the generator.↩︎