6 Position: Stop Making Unscientific AGI Performance Claims
Developments in the field of Artificial Intelligence (AI), and particularly large language models (LLMs), have created a ‘perfect storm’ for observing ‘sparks’ of Artificial General Intelligence (AGI) that are spurious. Like simpler models, LLMs distill meaningful representations in their latent embeddings that have been shown to correlate with external variables. Nonetheless, the correlation of such representations has often been linked to human-like intelligence in the latter but not the former. We probe models of varying complexity including random projections, matrix decompositions, deep autoencoders and transformers: all of them successfully distill information that can be used to predict latent or external variables and yet none of them have previously been linked to AGI. We argue and empirically demonstrate that the finding of meaningful patterns in latent spaces of models cannot be seen as evidence in favor of AGI. Additionally, we review literature from the social sciences that shows that humans are prone to seek such patterns and anthropomorphize. We conclude that both the methodological setup and common public image of AI are ideal for the misinterpretation that correlations between model representations and some variables of interest are ‘caused’ by the model’s understanding of underlying ‘ground truth’ relationships. We, therefore, call for the academic community to exercise extra caution, and to be keenly aware of principles of academic integrity, in interpreting and communicating about AI research outcomes.
Artificial General Intelligence, Large Language Models, Mechanistic Interpretability, Social Sciences
6.1 Introduction
In 1942, when anti-intellectualism was rising and the integrity of science was under attack, Robert K. Merton formulated four ‘institutional imperatives’ as comprising the ethos of modern science: universalism, meaning that the acceptance or rejection of claims entering the lists of science should not depend on personal or social attributes of the person bringing in these claims; “communism” [sic], meaning that there should be common ownership of scientific findings and one should communicate findings, rather than keeping them secret; disinterestedness, meaning that scientific integrity is upheld by not having self-interested motivations, and organized skepticism, meaning that judgment on the scientific contribution should be suspended until detached scrutiny is performed, according to institutionally accepted criteria (Merton et al. 1942). While the Mertonian norms may not formally be known to academics today, they still are implicitly being subscribed to in many ways in which academia has organized academic scrutiny; e.g., through the adoption of double-blind peer reviewing, and in motivations behind open science reforms.
At the same time, in the way in which academic research is disseminated in the AI and machine learning fields today, major shifts are happening. Where these research fields have actively adopted early sharing of preprints and code, the volume of publishable work has exploded to a degree that one cannot reasonably keep up with broad state-of-the-art, and social media influencers start playing a role in article discovery and citeability (Weissburg et al. 2024). Furthermore, because of major commercial stakes with regard to AI and machine learning technology, and e.g. following the enthusiastic societal uptake of products employing LLMs, such as ChatGPT, the pressure to beat competitors as fast as possible is only increasing, and strong eagerness can be observed in many domains to ‘do something with AI’ in order to innovate and remain current.
Where AI used to be a computational modeling tool to better understand human cognition (Rooij et al. 2023), the recent interest in AI and LLMs has been turning into one in which AI is seen as a tool that can mimic, surpass and potentially replace human intelligence. In this, the achievement of Artificial General Intelligence (AGI) has become a grand challenge, and in some cases, an explicit business goal. The definition of AGI itself is not as clear-cut or consistent; loosely, it is a phenomenon contrasting with ‘narrow AI’ systems, that were trained for specific tasks (Goertzel 2014). In practice, to demonstrate that the achievement of AGI may be getting closer, researchers have sought to show that AI models generalize to different (and possibly unseen) tasks, with little human intervention, or show performance considered ‘surprising’ to humans.
For example, Google DeepMind claimed their AlphaGeometry model (Trinh et al. 2024) reached a ‘milestone’ towards AGI. This model has the ability to solve complex geometry problems, allegedly without the need for human demonstrations during training. However, work such as this had been initially introduced in the 1950s (Zenil 2024): without the use of an LLM, logical inference systems proved 100% accurate in proving all the theorems of Euclidean Geometry, due to geometry being an axiomatically closed system. Therefore, while DeepMind created a powerfully fast geometry-solving machine, it is still far from AGI.
Generally, in the popularity of ChatGPT and the integration of generative AI in productivity tools (e.g. through Microsoft’s Copilot integrations in GitHub and Office applications), one also can wonder whether the promise of AI is more in computationally achieving general intelligence, or rather in the engineering of general-purpose tools1. Regardless, stakes and interests are high, e.g. with ChatGPT clearing nearly $1 billion in months of its release2.
When combining massive financial incentives with the presence of a challenging and difficult-to-understand technology, that aims towards human-like problem-solving and communication abilities, a situation arises that is fertile for the misinterpretation of spurious cues as hints towards AGI, or other qualities like sentience3 and consciousness. AI technology only becomes more difficult to understand as academic publishing in the space largely favors performance, generalization, quantitative evidence, efficiency, building on past work, and novelty (Birhane et al. 2022). As such, works that make it into top-tier venues tend to propose heavier and more complicated technical takes on tasks that (in the push towards generalizability) get more vague, while the scaling-up of data makes traceability of possible memorization harder. In a submission-overloaded reality, researchers may further get incentivized to oversell and overstate achievement claims. At the same time, while currently popular in literature, inherent complexity and opaqueness in technical solutions may fundamentally be unwise to pursue in high-stakes applications (Rudin 2019).
Noticing these trends, we as the authors of this article are concerned. We feel that the current culture of racing toward Big Outcome Statements in industry and academic publishing too much disincentivizes efforts toward more thorough and nuanced actual problem understanding. At the same time, as the outside world is so eager to adopt AI technology, (too) strong claims make for good sales pitches, but a question is whether there is indeed sufficient evidence for these claims. With successful AGI outcomes needing to look human-like, this also directly plays into risks of anthropomorphizing (the attribution of human-like qualities to non-human objects) and confirmation bias (the seeking-out and/or biased interpretation of evidence in support of one’s beliefs). In other words, it is very tempting to claim surprising human-like achievements of AI, and as humans, we are very prone to genuinely believing this. We therefore urge our fellow researchers to stop making unscientific AGI performance claims.
To strengthen our argument, in this paper, we first present related work in Section 6.2. We then consider a recently viral work (Gurnee and Tegmark 2023a) in which claims about the learning of world models by LLMs were made. In Section 6.3, we present several experiments that may invite similar claims on models yielding more intelligent outcomes than would have been expected—while at the same time indicating how we feel these claims should not be made. Furthermore, we present a review of social science findings in Section 6.4 that underline how prone humans are to being enticed by patterns that are not really there. Combining this with the way in which media portrayal of AI has tended towards science-fiction imagery of mankind-threatening robots, we argue that the current AI culture is a perfect storm for making and believing inflated claims, and call upon our fellow academics to be extra mindful and scrutinous about this. Finally, in Section 6.5, we propose specific structural and cultural changes to improve the current situation. Section 6.6 concludes.
6.3 Surprising Patterns in Latent Spaces?
In 2023, a research article went viral on the X4 platform (Gurnee and Tegmark 2023b). Through linear probing experiments, the claim was made that LLMs learned literal maps of the world. As such, they were considered to be more than ‘stochastic parrots’ (Bender et al. 2021) that can only correlate and mimic existing patterns from data, but not truly understand it. While the manuscript immediately received public criticism (Marcus 2023), and the revised, current version is more careful with regard to its claims (Gurnee and Tegmark 2023a), reactions on X seemed to largely exhibit excitement and surprise at the authors’ findings. However, in this section, through various simple examples, we make the point that observing patterns in latent spaces should not be a surprising revelation. After starting with a playful example of how easy it is to ‘observe’ a world model, we build up a larger example focusing on key economic indicators and central bank communications.
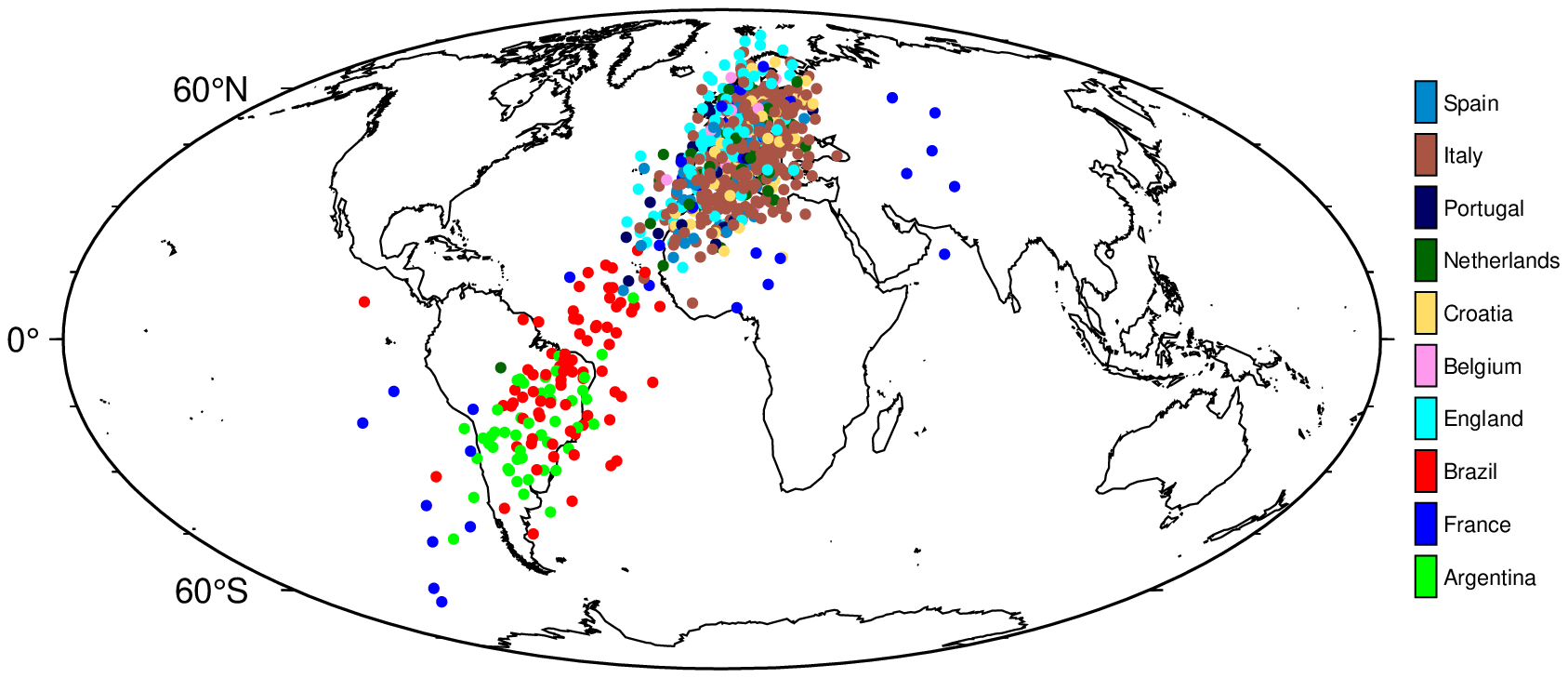
6.3.1 Are Neural Networks Born with World Models?
Gurnee and Tegmark (2023a) extract and visualize the alleged geographical world model by training linear regression probes on internal activations in LLMs (including Llama-2) for the names of places, to predict geographical coordinates associated with these places. Now, the Llama-2 model has ingested huge amounts of publicly available data from the internet, including Wikipedia dumps from the June-August 2022 period (Touvron et al. 2023). It is therefore highly likely that the training data contains geographical coordinates, either directly or indirectly. At the very least, we should expect that the model has seen features during training that are highly correlated with geographical coordinates. The model itself is essentially a very large latent space to which all features are randomly projected in the very first instance before being passed through a series of layers which are gradually trained for downstream tasks.
In our first example, we simulate this scenario, stopping short of training the model. In particular, we take the world_place.csv that was used in Gurnee and Tegmark (2023a), which maps locations/areas to their latitude and longitude. For each place, it also indicates the corresponding country. From this, we take the subset that contains countries that are currently part of the top 10 FIFA world ranking, and assign the current rank to each country (i.e., Argentina gets 1, France gets 2, …). To ensure that the training data only involves a noisy version of the coordinates, we transform the longitude and latitude data as follows: \(\rho \cdot \text{coord} + (1-\rho) \cdot \epsilon\) where \(\rho=0.5\) and \(\epsilon \sim \mathcal{N}(0, 5)\).
Next, we encode all features except the FIFA world rank indicator as continuous variables: \(X^{(n \times m)}\) where \(n\) is the number of samples and \(m\) is the number of resulting features. Additionally, we add a large number of random features to \(X\) to simulate the fact that not all features ingested by Llama-2 are necessarily correlated with geographical coordinates. Let \(d\) denote the final number of features, i.e. \(d=m+k\) where \(k\) is the number of random features.
We then initialize a small neural network, considered a projector, mapping from \(X\) to a single hidden layer with \(h<d\) hidden units and sigmoid activation, and from there, to a lower-dimensional output space. Without performing any training on the projector, we simply compute a forward pass of \(X\) and retrieve activations \(\mathbf{Z}^{(n\times h)}\). Next, we perform the linear probe on a subset of \(\mathbf{Z}\) through Ridge regression: \(\mathbf{W} = (\mathbf{Z}_{\text{train}}'\mathbf{Z}_{\text{train}} + \lambda \mathbf{I}) (\mathbf{Z}_{\text{train}}'\textbf{coord})^{-1}\), where \(\textbf{coord}\) is the \((n \times 2)\) matrix containing the longitude and latitude for each sample. A hold-out set is reserved for testing, on which we compute predicted coordinates for each sample as \(\widehat{\textbf{coord}}=\mathbf{Z}_{\text{test}}\mathbf{W}\) and plot these on a world map (Figure 6.1).
While the fit certainly is not perfect, the results do indicate that the random projection contains representations that are useful for the task at hand. Thus, this simple example illustrates that meaningful target representations should be recoverable from a sufficiently large latent space, given the projection of a small number of highly correlated features. Similarly, Alain and Bengio (2016) observe that even before training a convolutional neural network on MNIST data, the layer-wise activations can already be used to perform binary classification. In fact, it is well-known that random projections can be used for prediction tasks (Dasgupta 2013).
This first experiment—and indeed the practice of probing LLMs that have seen vast amounts of data—can be seen as a form of inverse problem and common caveats such as non-uniqueness and instability apply (Haltmeier and Nguyen 2023). Regularization can help mitigate these caveats (OM 2001), but we confess that we did not carefully consider the parameter choice for \(\lambda\), nor has this been carefully studied in the related literature to the best of our knowledge.
6.3.2 PCA as a Yield Curve Interpreter
We now move to a concrete application domain: Economics. Here, the yield curve, plotting the yields of bonds against their maturities, is a popular tool for investors and economists to gauge the health of the economy. The yield curve’s slope is often used as a predictor of future economic activity: a steep yield curve is associated with a growing economy, while a flat or inverted yield curve is associated with a contracting economy. To leverage this information in downstream modelling tasks, economists regularly use PCA to extract a low-dimensional projection of the yield curve that captures relevant variation in the data (e.g. Berardi and Plazzi (2022), Kumar (2022) and Crump and Gospodinov (n.d.)).
To understand the nature of this low-dimensional projection, we collect daily Treasury par yield curve rates at all available maturities from the US Department of the Treasury. Computing principal components involves decomposing the matrix of all yields \(\mathbf{r}\) into a product of its singular vectors and values: \(\mathbf{r}=\mathbf{U}\Sigma\mathbf{V}^{\prime}\). Let us simply refer to \(\mathbf{U}\), \(\Sigma\) and \(\mathbf{V}^{\prime}\) as latent embeddings of the yield curve.
The upper panel in Figure 6.2 shows the first two principal components of the yield curves of US Treasury bonds over time. Vertical stalks indicate key dates related to the Global Financial Crisis (GFC). During its onset, on 27 February 2007, financial markets were in turmoil following a warning from the Federal Reserve (Fed) that the US economy was at risk of a recession. The Fed later reacted to mounting economic pressures by gradually reducing short-term interest rates to unprecedented lows. Consequently, the average level of yields decreased and the curve steepened. In Figure 6.2, we can observe that the first two principal components appear to capture this level shift and steepening, respectively. In fact, they are strongly positively correlated with the actual observed first two moments of the yield curve (lower panel of Figure 6.2).
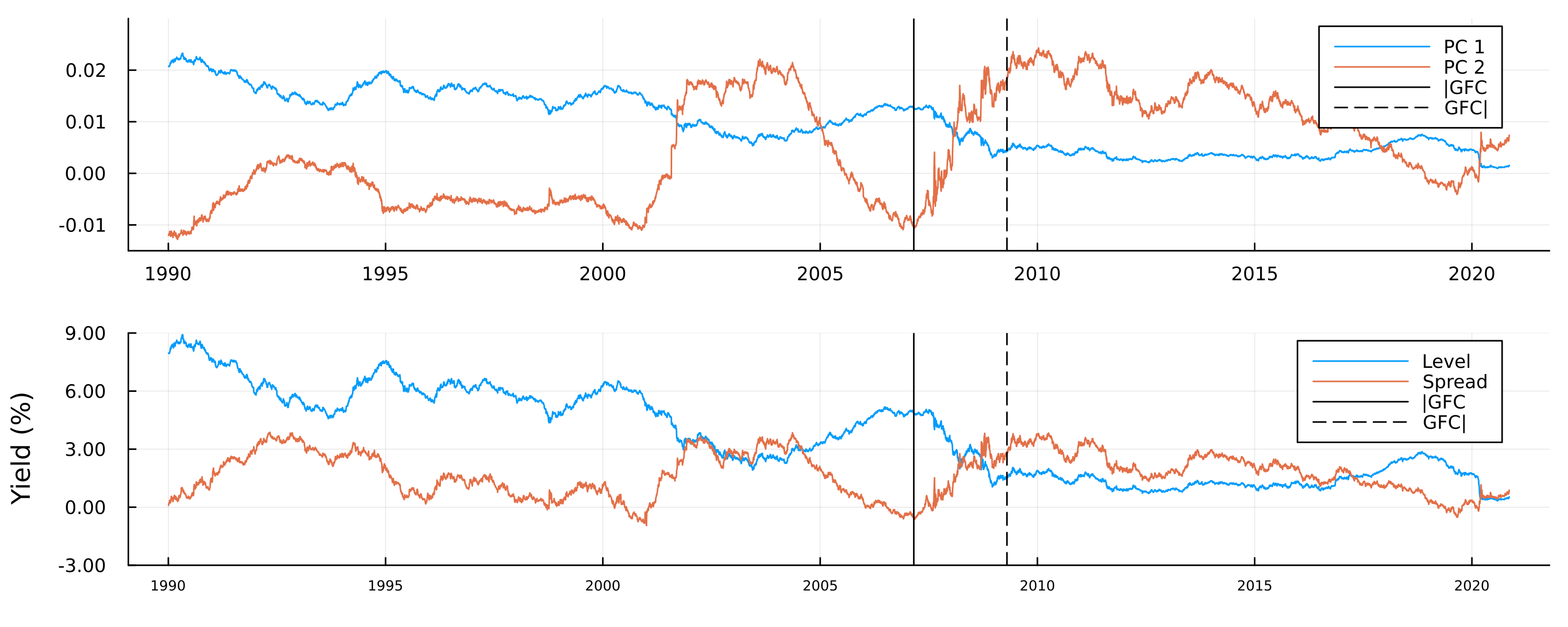
Again, it should not be surprising that these latent embeddings are meaningful: by construction, principal components are orthogonal linear combinations of the data itself, each of which explains most of the residual variance after controlling for the effect of all previous components.
6.3.3 LLMs for Economic Sentiment Prediction
So far, we considered simple linear data transformations. One might argue that this does not really involve latent embeddings in the way they are typically thought of in the context of deep learning. In the appendix, we present an additional experiment in which we more explicitly seek neural network-based representations that will be useful for downstream tasks. Here, we continue with an example in which LLMs may be used for economic sentiment prediction.
Closely following the approach in Gurnee and Tegmark (2023a), we apply it to the novel Trillion Dollar Words (Shah, Paturi, and Chava 2023) financial dataset, containing a curated selection of sentences formulated and communicated to the public by the Fed through speeches, meeting minutes and press conferences. (Shah, Paturi, and Chava 2023) use this dataset to train a set of LLMs and rule-based models to classify sentences as either ‘dovish’, ‘hawkish’ or ‘neutral’. In the context of central banking, ‘hawkishness’ is typically associated with tight monetary policy: in other words, a ‘hawkish’ stance on policy favors high interest rates to limit the supply of money and thereby control inflation. The authors first manually annotate a sub-sample of the available data and then fine-tune various models for the classification task. Their model of choice, FOMC-RoBERTa (a fine-tuned version of RoBERTa (Liu et al. 2019)), achieves an \(F_1\) score of around \(>0.7\) on the test data. To illustrate the potential usefulness of the learned classifier, they use predicted labels for the entire dataset to compute an ad-hoc, count-based measure of ‘hawkishness’. This measure is shown to correlate with key economic indicators in the expected direction: when inflationary pressures rise, the measured level of ‘hawkishness’ increases, as central bankers react by raising interest rates to bring inflation back to target.
6.3.3.1 Linear Probes
We now use linear probes to assess if the fine-tuned model has learned associative patterns between central bank communications and key economic indicators. Therefore, we further pre-process the data provided by Shah, Paturi, and Chava (2023) and use their proposed model to compute activations of the hidden state, on the first entity token for each layer. We have made these available and easily accessible through a small Julia package: TrillionDollarWords.jl.
For each layer, we compute linear probes through Ridge regression on two inflation indicators (the Consumer Price Index (CPI) and the Producer Price Index (PPI)) and US Treasury yields at different levels of maturity. To allow comparison with Shah, Paturi, and Chava (2023), we let yields enter the regressions in levels. To measure price inflation we use percentage changes proxied by log differences. To mitigate issues related to over-parameterization, we follow the recommendation in Alain and Bengio (2016) to first reduce the dimensionality of the computed activations. In particular, we restrict our linear probes to the first 128 principal components of the embeddings of each layer. To account for stochasticity, we use an expanding window scheme with 5 folds for each indicator and layer. To avoid look-ahead bias, PCA is always computed on the sub-samples used for training the probe.
Figure 6.3 shows the out-of-sample root mean squared error (RMSE) for the linear probe, plotted against FOMC-RoBERTa’s \(n\)-th layer. The values correspond to averages across cross-validation folds. Consistent with related work (Alain and Bengio 2016; Gurnee and Tegmark 2023a), we observe that model performance tends to be higher for layers near the end of the transformer model. Curiously, for yields at longer maturities, we find that performance eventually deteriorates for the very final layers. We do not observe this for the training data, so we attribute this to overfitting.
It should be noted that performance improvements are generally of small magnitude. Still, the overall qualitative findings are in line with expectations. Similarly, we also observe that these layers tend to produce predictions that are more positively correlated with the outcome of interest and achieve higher mean directional accuracy (MDA). Upon visual inspection of the predicted values, we conclude the primary source of prediction errors is low overall sensitivity, meaning that the magnitude of predictions is generally too small.
To better assess the predictive power of our probes, we compare their predictions to those made by simple autoregressive models. For each layer, indicator and cross-validation fold, we first determine the optimal lag length based on the training data using the Bayes Information Criterium with a maximal lag length of 10. These are not state-of-the-art forecasting models, but they serve as a reasonable baseline. For most indicators, probe predictions outperform the baseline in terms of average performance measures. After accounting for variation across folds, however, we generally conclude that the probes neither significantly outperform nor underperform. Detailed results, in which we also perform more explicit statistical testing, can be found in the appendix.


6.3.3.2 Sparks of economic understanding?
Even though FOMC-RoBERTa, which is substantially smaller than the models tested in Gurnee and Tegmark (2023a), was not explicitly trained to uncover associations between central bank communications and the level of consumer prices, it appears that the model has distilled representations that can be used to predict inflation (although they certainly will not win any forecasting competitions). So, have we uncovered further evidence that LLMs “aren’t mere stochastic parrots”? Has FOMC-RoBERTa developed an intrinsic ‘understanding’ of the economy just by ‘reading’ central bank communications? Thus, can economists readily adopt FOMC-RoBERTa as a domain-relevant tool?
We are having a very hard time believing that the answer to either of these questions is ‘yes’. To argue our case, we will now produce a counter-example demonstrating that, if anything, these findings are very much in line with the parrot metaphor. The counter-example is based on the following premise: if the results from the linear probe truly were indicative of some intrinsic ‘understanding’ of the economy, then the probe should not be sensitive to random sentences that are most definitely not related to consumer prices.
To test this, we select the best-performing probe trained on the final-layer activations for each indicator. We then make up sentences that fall into one of these four categories: Inflation/Prices (IP)—sentences about price inflation, Deflation/Prices (DP)—sentences about price deflation, Inflation/Birds (IB)—sentences about inflation in the number of birds and Deflation/Birds (DB)—sentences about deflation in the number of birds. A sensible sentence for category DP, for example, could be: “It is essential to bring inflation back to target to avoid drifting into deflation territory.”. Analogically, we could construct the following sentence for the DB category: “It is essential to bring the numbers of doves back to target to avoid drifting into dovelation territory.”. While domain knowledge suggests that the former is related to actual inflation outcomes, the latter is, of course, completely independent of the level of consumer prices. Detailed information about the made-up sentences can be found in the appendix.
In light of the encouraging results in Figure 6.3, we should expect the probe to predict higher levels of inflation for activations for sentences in the IP category, than for sentences in the DP category. If this was indicative of true intrinsic ‘understanding’ as opposed to memorization, we would not expect to see any significant difference in predicted inflation levels for sentences about birds, independent of whether their numbers are increasing. More specifically, we would not expect the probe to predict values for sentences about birds that are substantially different from the values it can be expected to predict for actual white noise.
To get to this last point, we also generate many probe predictions for samples of noise. Let \(f: \mathcal{A}^k \mapsto \mathcal{Y}\) denote the linear probe that maps from the \(k\)-dimensional space spanned by \(k\) first principal components of the final-layer activations to the output variable of interest (CPI growth in this case). Then we sample \(\varepsilon_i \sim \mathcal{N}(\mathbf{0},\mathbf{I}^{(k \times k)})\) for \(i \in [1,1000]\) and compute the sample average. We repeat this process \(10000\) times and compute the median-of-means to get an estimate for \(\mathbb{E}[f(\varepsilon)]=\mathbb{E}[y|\varepsilon]\), that is the predicted value of the probe conditional on random noise.
Figure 6.4 shows the results of this small test: it shows predicted inflation levels subtracted by \(\mathbb{E}[f(\varepsilon)]\). The median linear probe predictions for sentences about inflation and deflation are indeed substantially higher and lower, respectively than for random noise. Unfortunately, the same is true for sentences about the inflation and deflation in the number of birds, albeit to a somewhat lower degree. This finding holds for both inflation indicators and to a lesser degree also for yields at different maturities, at least qualitatively.
6.5 Outlook
Reflecting on the previous two sections, we make the following concrete recommendations for future research:
(Acknowledgement of Human Bias) Researchers should be mindful of, and explicit about, risks of human bias and anthropomorphization in interpreting results, which both can be done as part of the results discussion, but also in a dedicated ‘limitations’ section.
(Stronger Testing) Researchers should refrain from drawing premature conclusions about AGI, unless these are based on strong hypothesis tests.
(Epistemologically Robust Standards) We call for more precise definitions of terms like ‘intelligence’ and ‘AGI’, and publicly accountable and collaborative iterations over how we will measure them, with explicit room for independent reviewing and external auditing by the broader community.
Moreover, we believe that structural and cultural changes are in order to reduce current incentives to chase Big Statement Outcomes in AI research and industry. Our broadest and perhaps most ambitious goal is for our research community to move away from authorship and instead embrace contributorship. This argument has been raised long before in other research communities (Smith 1997) and more recently within our own (Liem and Demetriou 2023). Specifically, Liem and Demetriou (2023) argue that societally impactful scientific insights should be treated as open-source software artifacts. The open-source community sets a positive example of how scientific artifacts should be published in many different ways. Not only does it adequately reward small contributions but it also naturally considers negative results (bugs) as part of the scientific process. Similarly, code reviews are considered so integral to the process that they typically end up as accredited contributions to projects. Open review platforms like OpenReview are a step in the right direction, but still fall short of what we know is technically feasible. Finally, software testing is, of course, not only essential but often obligatory before contributions are accepted and merged. As we have pointed out repeatedly in this work, any claims about AGI demand proper strong hypothesis tests. It is important to remember that AGI remains the alternative hypothesis and that the burden of proof therefore lies with those making strong claims.
6.6 Conclusion
As discussed above, AI research and development outcomes can easily be over-interpreted, both from a data perspective and because of human biases and interests. Academic researchers are not free from such biases. Thus, we call for the community to create explicit room for organized skepticism.
For research that seeks to explain a phenomenon, clear hypothesis articulation and strong null hypothesis formulation are needed. If claims of human-like or superhuman intelligence are made, these should be subject to severe tests (Claesen et al. 2022) that go beyond the display of surprise. Apart from focusing on getting novel improvements upon state-of-the-art published, organizing red-teaming activities as a community may help in incentivizing and normalizing constructive adversarial questioning. As the quest for AGI is so deeply rooted in human-like recognition, adding our voice to emerging calls to be vigilant in communication (Shanahan 2024), we put in an explicit word of warning about the use of terminology. Many terms used in current AGI research (e.g. emergence, intelligence, learning, ‘better than human’ performance) have a common understanding in specialized research communities, but have bigger, anthropomorphic connotations in laypersons. In fictional media, depictions of highly intelligent AI have for long been going around. In a study of films featuring robots, defined as "...an artificial entity that can sense and act as a result of (real-world or fictional) technology...", in the 134 most highly rated science-fiction movies on IMDB, 74 out of the 108 AI-robots studied had a humanoid shape, and 68 out of those had sufficient intelligence to interact at an almost human-level (Saffari et al. 2021). The authors identify human-like communication and the ability to learn as essential abilities in the depiction of AI agents in movies. They further show a common plot: humans perceive the AI agents as inferior, despite their possession of self-awareness and the desire to survive, which fuels the central conflict of the film, wherein humanity is threatened by AI superior in both intellect and physical abilities. It is often noted that experts and fictional content creators interact, informing and inspiring each other (Saffari et al. 2021; Neri and Cozman 2020).
This image also permeates present-day non-fictional writings on AI, which often use anthropomorphized language (e.g. “ever more powerful digital minds” in the ‘Pause Giant AI Experiments’ open letter (Future of Life Institute 2023)). In the news, we witness examples of humans falling in love with their AI chatbots (Morrone 2023; Steinberg 2023). The same news outlets discuss the human-like responses of Microsoft’s Bing search engine, which had at that point recently been adopting GPT-47. The article (Cost 2023), states “As if Bing wasn’t becoming human enough” and goes on to claim it told them it loves them. Here, AI experts and influencers also have considerable influence on how the narrative unfolds on social media: according to Neri and Cozman (2020), actual AI-related harms did not trigger viral amplification (e.g. the death of an individual dying while a Tesla car was in autopilot, or the financial bankruptcy of a firm using AI technology to execute stock trades). Rather, potential risks expressed by someone perceived as having expertise and authority were amplified, such as statements made by Stephen Hawking during an interview in 2014.
We as academic researchers carry great responsibility for how the narrative will unfold, and what claims are believed. We call upon our colleagues to be explicitly mindful of this. As attractive as it may be to beat the state-of-the-art with a grander claim, let us return to the Mertonian norms, and thus safeguard our academic legitimacy in a world that only will be eager to run with made claims.
A Swiss army knife is an effective general-purpose tool, without people wondering whether it exhibits intelligence.↩︎
https://www.bloomberg.com/news/articles/2023-08-30/openai-nears-1-billion-of-annual-sales-as-chatgpt-takes-off↩︎
https://www.scientificamerican.com/article/google-engineer-claims-ai-chatbot-is-sentient-why-that-matters/↩︎
https://twitter.com/wesg52/status/1709551516577902782?s=20↩︎
https://ourworldindata.org/grapher/annual-scholarly-publications-on-artificial-intelligence?time=2010..2021↩︎
Retrieved 23/01/23 using the search string "TITLE-ABS-KEY ( ( machine AND learning ) OR ( artificial AND intelligence ) OR ai ) AND PUBYEAR \(>\) 2009 AND PUBYEAR \(<\) 2024 " from the SCOPUS database.↩︎
A large multimodal language model from OpenAI https://openai.com/research/gpt-4.↩︎